El cuerpo humano consta de billones de células, cada una de las cuales tiene el mismo manual de instrucciones por dentro, una secuencia de ADN de tres mil millones de letras de largo. Hay compuestos químicos, incluidas las proteínas, que modifican la interpretación del manual de instrucciones, por ejemplo, uniéndose al ADN y activando o desactivando un gen. Las modificaciones hechas por los compuestos químicos que le dicen al genoma qué hacer se conocen colectivamente como el epigenoma.
El epigenoma es la razón por la cual una célula neuronal en el cerebro y una célula muscular en el corazón tienen formas y tamaños completamente diferentes a pesar de tener el mismo manual de instrucciones. A medida que las células se especializan, su epigenoma comienza a cambiar y divergir del epigenoma de otros tipos de células. Cuando las células especializadas se dividen, gran parte de su epigenoma se transmite a la siguiente generación de células, lo que resulta en tejidos enteros con un conjunto único de modificaciones genómicas, también conocidas como "marcas" epigenómicas.
Los cambios en el epigenoma pueden causar o ser el resultado de enfermedades, por lo que trazar las ubicaciones y comprender la función de las marcas epigenómicas es fundamental para la biología humana. La creación de mapas epigenómicos de cada tejido es vital para el futuro de la medicina personalizada, ya que algún día puede permitir a los médicos determinar la salud de un individuo o predecir la reacción de un paciente a un fármaco.
Una colaboración internacional de investigación ha abordado este reto catalogando el epigenoma humano de manera comprensiva, trazando toda la colección de marcas epigenómicas en más de 25 tipos diferentes de tejidos en todo el cuerpo humano. Los hallazgos, publicados hoy en la revista Cell, proporcionan el mapa más completo del epigenoma humano hasta la fecha.
"Cada individuo es único y tiene un grado de variación, lo que significa que el epigenoma de mi hígado diferirá del suyo a pesar de que es el mismo tejido. En un estado de enfermedad, estos cambios serán aún más pronunciados, y este nuevo recurso nos ayudará a medir estas diferencias para comprender los mecanismos de la enfermedad”, afirma el Dr. Roderic Guigó, coautor principal del estudio e investigador del Centro de Regulación Genómica en Barcelona.
El conjunto de datos fue generado secuenciando los genomas de cuatro donantes y estudiando la actividad de todos los genes y sus regiones reguladoras en 30 tipos diferentes de tejidos, incluyendo datos de tejidos difíciles de obtener como el pulmón. Conocido como EN-TEx, los epigenomas personales generados por el proyecto pueden usarse como referencia y combinarse con otras anotaciones del genoma humano para discernir si una variante genética en un individuo en particular contribuye a la salud o la enfermedad.
Una de las ventajas únicas de EN-TEx es que es el primer recurso de este tipo que incluye información de ambas copias de los cromosomas de cada individuo. Esto significa que, por primera vez, se puede discernir el impacto de las variantes genéticas heredades del lado materno o del lado paterno.
"De media, un individuo tiene entre 4 y 4,5 millones de mutaciones, pero es difícil saber cuáles son dañinas. Este recurso nos permite por primera vez saber qué mutaciones ha heredado un individuo de mamá y papá, y entender cuáles pueden tener un posible impacto en la salud", explica la doctora Beatrice Borsari, quien llevó a cabo el trabajo durante su doctorado en el Centro de Regulación Genómica en Barcelona y actualmente es investigadora postdoctoral en la Universidad de Yale en los Estados Unidos.
EN-TEx supera una de las limitaciones del genoma de referencia original publicado en el año 2003. El genoma de referencia se ensambló usando solo una copia de cada cromosoma, lo que significa que las variantes genéticas que son específicas de una de las dos copias de un cromosoma, conocidas como variantes alelo-específicas (AS), se omitieron o se representaron incorrectamente. Las sucesivas iniciativas a gran escala, como los proyectos ENCODE o GTEx, utilizaron el genoma de referencia como base para sus hallazgos y tampoco incluyeron estos tipos de variantes genéticas. El equipo de investigación utilizó el recurso para identificar y localizar más de un millón de variantes de AS en el genoma, ampliando el catálogo conocido.
Una de las aplicaciones del recurso EN-TEx es predecir el comportamiento de las secuencias de ADN que controlan cómo se comportan los genes, también conocidas como loci de rasgos cuantitativos de expresión o simplemente “eQTLs”. Aprovechando los datos en EN-TEx, el equipo de investigación utilizó el aprendizaje automático para construir una herramienta que puede transferir eQTL de un tejido a otro. Es decir, ahora es posible detectar cómo ciertas secuencias de ADN influyen en el comportamiento de los genes en los tejidos midiéndolos a partir de una muestra de sangre, una herramienta útil para desarrollar nuevas terapias y tratamientos para tejidos difíciles de estudiar, como el corazón o el pulmón.
Otra aplicación importante de EN-TEx es poder predecir el comportamiento de una clase de proteínas que modifican el genoma conocidas como factores de transcripción. Las mutaciones o cambios en la regulación de los factores de transcripción pueden conducir a una amplia gama de enfermedades, incluyendo el cáncer, los trastornos metabólicos y trastornos inmunes. Como resultado, los factores de transcripción son dianas terapéuticas de gran relevancia.
El equipo utilizó EN-TEx para desarrollar un modelo de aprendizaje profundo que puede predecir si una variante puede interrumpir el sitio de unión de los factores de transcripción. El modelo muestra que se debe mirar más allá del sitio de unión en sí y también considerar la zona alrededor del sitio. El equipo descubrió que la clave para determinar si un sitio de unión se interrumpiría era la presencia de las secuencias de unión de otros factores regulatorios cercanos.
"Piense en los factores regulatorios como las patas del módulo lunar", afirma el doctor Mark Gerstein, profesor de informática biomédica en la Universidad de Yale en un comunicado de prensa redactado por la Facultad de Medicina de Yale. "Si tiene cuatro patas y una no funciona, las otras tres pueden anclar la pata defectuosa. Del mismo modo, el anclaje de otros factores reguladores podría estabilizar el sitio de unión, haciéndolo menos sensible a las variantes.”
Una limitación del recurso es que solo cuatro personas de ascendencia europea fueron perfiladas para la generación de los datos. Al equipo le gustaría eventualmente ampliar su estudio para abarcar a cientos de individuos con genealogías más diversas.
El estudio fue financiado por el Instituto Nacional de Investigación del Genoma Humano (NHGRI) de los Estados Unidos de América y dirigido por equipos de investigación de la Universidad de Yale, la Universidad de Harvard, el Instituto de Tecnología de Massachusetts (MIT), la Universidad Johns Hopkins y el Laboratorio Cold Spring Harbor en los Estados Unidos, así como el Centro de Regulación Genómica, en Barcelona.
Entre las instituciones colaboradoras se incluyen el Baylor College of Medicine, el Instituto de Tecnología de California, el Instituto del Cáncer Dana-Farber, el Instituto Europeo de Bioinformática, el Instituto HudsonAlpha de Biotecnología, el Instituto de Tecnología de Nueva York, la Universidad de Stanford, la Universidad de California, Irvine, la Universidad de California, San Diego, la Universidad de Hong Kong, la Facultad de Medicina de la Universidad de Massachusetts, la Universidad de Toronto, Canadá, y la Universidad de Washington en Seattle.
El Centro de Regulación Genómica participó en el diseño del proyecto y contribuyó en muchas facetas del proyecto de investigación como, por ejemplo, en el desarrollo de los modelos para transferir eQTLs entre tejidos, y en la mejora de la precisión del análisis de datos obtenidos de genomas individuales en lugar del genoma de referencia.
"Cataluña ha participado de forma relevante en iniciativas genómicas a gran escala en los últimos veinte años, incluido el Proyecto Genoma Humano. La genómica es uno de los campos que tendrá el mayor impacto en la vida de las personas en el siglo 21. Hemos demostrado que podemos desempeñar un papel importante en estos proyectos, pero también tenemos que hacernos cargo y lanzar nuestros propios proyectos a gran escala. Estamos en condiciones de hacerlo. Para eso, necesitamos más recursos, pero sobre todo visión de futuro y ambición", concluye el Dr. Guigó.
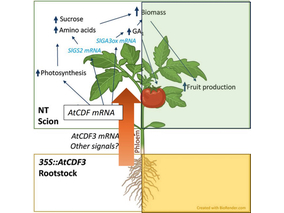
El gen AtCDF3 promueve una mayor producción de az...
Un estudio con datos de los últimos 35 años, ind...
Un equipo de investigadores de la Universidad Juli...
En nuestro post hablamos sobre este interesante tipo de célula del si...

Gracias al estudio de un grupo excepcional de personas dentro de los d...