Hasta ahora, los mejores sintetizadores de canto estaban basados en muestras o en modelos estadísticos. Los primeros se caracterizan por juntar pequeños fragmentos de grabaciones, como si formaran un gran puzzle, pero tienen problemas a la hora de generar un canto fluido sin discontinuidades. Los modelos estadísticos, por su parte, se basan en un cuidadoso análisis estadístico de las características sonoras de las grabaciones. Son capaces de generar canto fluido sin discontinuidades, pero tienen problemas para generar detalles y matices.
Jordi Bonada y Merlijn Blaauw, investigadores del Music Information Research Lab (MIRLab) vinculado al Grupo de Investigación en Tecnología Musical (MTG) de la UPF, han desarrollado un sistema innovador que utiliza redes neuronales de última generación especializadas en señales acústicas. Este nuevo modelo permite unir mejor los dos aspectos principales de los sintetizadores de canto tradicionales, y es capaz de generar canto fluido con detalles y matices, y sin discontinuidades.
Además, rompiendo la tendencia general en redes neuronales de requerir muchas horas de grabación para crear modelos de voz, el sistema propuesto es capaz de modelar canto con pocas grabaciones, 15 minutos en español y 35 en inglés. Incorpora también un algoritmo que permite crear canto sintético alrededor de 20 veces más rápido que en tiempo real, lo que lo convierte en un sistema claramente competitivo en términos de calidad sonora y eficiencia.
La evaluación y validación del nuevo sistema se ha realizado a través de un experimento de escucha con 18 oyentes. El resultado ha sido que el nuevo método es claramente preferido a otros sistemas existentes basados en muestras y en síntesis estadísticas paramétricas.
Los dos investigadores, Bonada y Blaauw, presentarán el sintetizador en el próximo congreso internacional Interspeech 2017, que se celebrará del 20 al 24 de agosto en Estocolmo (Suecia). El encuentro quiere proporcionar un enfoque amplio en torno a los problemas de comunicación en relación al habla.
Demostraciones de su funcionamiento
Trabajo de referencia: Bonada y Blaauw; A neural parametric singing synthesizer; arxiv.org
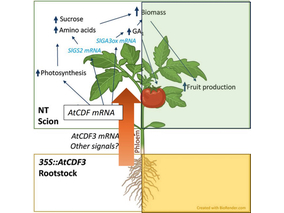
El gen AtCDF3 promueve una mayor producción de az...
Un estudio con datos de los últimos 35 años, ind...
Un equipo de investigadores de la Universidad Juli...
En nuestro post hablamos sobre este interesante tipo de célula del si...

Horizon ha puesto en funcionamiento una nueva planta dedicada íntegra...