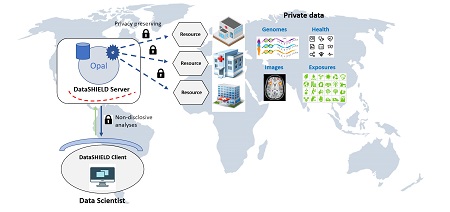
Big data, or in other words, the capacity to analyse a large amount and variety of data at great speed, has the potential of revolutionising biomedicine and healthcare. However, several challenges remain before big data achieves its full potential. One of them is how to share data from study participants between different researchers or institutions, while ensuring they are protected and comply with legal frameworks in the UE and elsewhere. Another challenge is choosing between sending those data to a centralised repository (or data warehouse) to facilitate their analysis, or not. The advantage of not doing so, and of leaving them in their original servers, is that the physical data remain under the control of their custodian, and the data can be updated quickly without the need of resending them to a central location.
The DataShield platform, developed over the last 10 years in the UK, enables this kind of “federated” analysis: data from research studies stay on a server at each of the institutions that are responsible for the data, and the person analysing the data cannot access individual-level information of the study participants. “However, the analysis of big data with DataSHIELD has been limited by how the data are stored, and by the analysis capabilities of the platform,” says Juan Ramón González, ISGlobal researcher and senior author of the study.
To circumvent this problem, González, in collaboration with Yannick Marcon from Epigeny and the DataShield Core Team led by Paul Burton, developed a new architecture for DataShield (and its data warehouse called Opal) in order to allow large, complex datasets to be used at their original location, in their original format and with external computing facilities . The authors then provide some real-life examples of how this new tool can be used in geospatial projects and genomics. Actually, this study was supported by the VEIS project (funded by ERDF), which aims to facilitate the integration and analysis of data from the European Genome Archive. It could also be used in many other disciplines where confidentiality is an issue, say the authors. For example, for the analysis of neuroimages, or combining big data and machine learning for clinical diagnosis.
“In particular, our tool could be applied to a huge European-funded genomics initiative called Beyond One Million Genomes (B1MG),” says González. The initiative, signed by 22 European countries, seeks to give cross-border access to one million sequenced genomes by 2022 . Launched by the ELIXIR organisation, it seeks to go beyond genomics and further the development of a data sharing infrastructure to “help clinicians pursue personalised medicine and benefit their patients, scientists to better understand diseases, and innovators to contribute to and boost the European economy”. “The framework we describe in the study responds fittingly to this objective,” says González.
To help researchers use this framework, the developers present an online book ( https://isglobal-brge.github.io/resource_bookdown ).
The VEIS project has been co-financed in 50% by the European Regional Development Fund of the European Union within the framework of the ERDF Operational Programme of Catalonia 2014-2020, with the support of the Generalitat de Catalunya.
Marcon Y, Bishop T, Avraam D, Escriba-Montagut X, Ryser-Welch P, et al. (2021) Orchestrating privacy-protected big data analyses of data from different resources with R and DataSHIELD. PLOS Computational Biology 17(3): e1008880. https://doi.org/10.1371/journal.pcbi.1008880

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
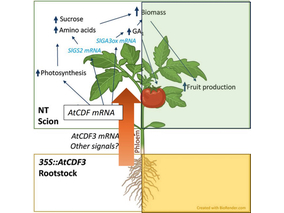
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

New study finds an association between higher temperatures early in li...










