En un trabajo reciente, investigadores de la Escuela Politécnica Superior (EPS) de la Universidad Autónoma de Madrid (UAM) han transformado variables de optimización bayesiana habilitando el uso de procesos gaussianos con variables enteras y categóricas. Estos resultados podrían significar una mejora de modelos probabilísticos, y por tanto en mejores resultados de optimización.
Como parte del trabajo, los autores han comprobado mejoras en el rendimiento de algoritmos de aprendizaje automático, pero los resultados podrían aplicarse otro tipo de problemas de optimización, como la búsqueda de nuevos materiales, la búsqueda de moléculas para crear nuevas medicinas, o incluso la creación automática de recetas de cocina.
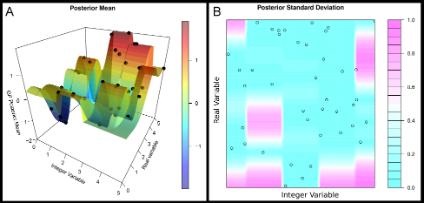
La clave de la transformación propuesta por los investigadores de la EPS-UAM reside en asignar a cada posible configuración un punto determinado del espacio: El cálculo de la distribución predictiva implica realizar comparaciones de proximidad entre configuraciones; al realizar las comparaciones en ese espacio transformado, se obtiene como resultado un cálculo más preciso de la distribución predictiva del proceso gaussiano para cada configuración.
“La transformación consiste, en el caso de variables enteras, en la partición de la recta real en tantos intervalos como valores tenga la variable entera, y se asigna uno de esos intervalos como valor, por simple redondeo”, explican los autores.
“En el caso de variables categóricas —detallan— se añaden tantas dimensiones reales como posibles valores tenga la variable, y se asigna como valor una configuración donde la dimensión correspondiente a la categoría vale uno y todas las demás dimensiones valen cero”.
Los investigadores también llevaron a cabo una serie de experimentos sintéticos y reales, donde compararon los resultados obtenidos cuando la transformación propuesta es utilizada y cuando no. Los experimentos muestran mejores resultados cuando la transformación propuesta es utilizada.
En concreto, el trabajo ha logrado mejorar significativamente el error de generalización obtenido por una red neuronal y un conjunto de clasificadores en un popular conjunto de datos de reconocimiento de dígitos. Gracias a esto, los problemas de optimización bayesiana con variables enteras y categóricas pueden ser resueltos de manera más eficiente y generando soluciones de mayor calidad.
Optimización bayesiana
La optimización bayesiana es una técnica usada en problemas de optimización en los cuales se desconoce la expresión analítica de la función a optimizar. Cada evaluación de esta función es muy costosa, bien en tiempo o dinero, y la misma configuración produce evaluaciones distintas, es decir, pueden estar contaminadas por ruido.
Un gran número de problemas de optimización tiene estas características. Un ejemplo es optimizar el controlador de un robot autónomo para maximizar la velocidad de desplazamiento. En este caso evaluar la función objetivo implicaría, o bien llevar a cabo una simulación con el robot, o bien un experimento real con el mismo. Además, el resultado del experimento puede ser distinto cada vez, dependiendo por ejemplo de las condiciones del entorno.
La optimización bayesiana se ha hecho popular para optimizar los hiper-parámetros de los algoritmos de aprendizaje automático, con el objetivo de minimizar el error de generalización. Por ejemplo, en el caso de una red neuronal, se puede optimizar el error en base al número de capas de la red, la función de activación, regularizadores, número de neuronas, tasa de aprendizaje y otros parámetros.
La optimización bayesiana utiliza un modelo probabilístico de la función objetivo, típicamente un proceso gaussiano. Este modelo se va actualizando con la información de las evaluaciones realizadas, facilitando predicciones e incertidumbre para todas las posibles configuraciones de la función objetivo. En base a esta información, se usa un criterio que recomienda nuevas evaluaciones a realizar con el objetivo de resolver el problema en el menor número posible de evaluaciones.
El problema de los procesos gaussianos es que asumen que todas las variables de entrada de la función objetivo son reales. De este modo, solo se podría emplear esta técnica en problemas con variables reales y no con variables que tomen valores en los enteros, como el número de capas en una red neuronal, o la función de activación a considerar en cada neurona. Esto limita su uso en aplicaciones reales.
_____________________
Referencia bibliográfica:
Garrido-Merchán, E.C., Hernández-Lobato, D. 2020. Dealing with categorical and integer-valued variables in Bayesian Optimization with Gaussian processes. Neurocomputing 380 (7), 20-35.

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
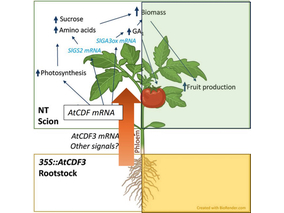
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

A paper published in Alzheimer’s & Dementia: The Journal of the Alzh...










