Nominal variables are a type of categorical variables that take different values for which the order does not matter. They are variables that help to differentiate some elements from others by their qualities and not by their quantity or their degree of possession of a certain modality.
Some examples of classic nominal variables in clinical trials are the randomization group, sex, diagnosis, type of treatment, hospital where the patients were recruited, whether a certain medical test was performed, type of adverse event, etc. Other nominal variables can be any identifying variable, for example: person’s full name, ID card number, order number, telephone number, medical history number, etc.
First, describing…
The nominal variables descriptive analysis usually begins with the study of the distribution of the number of cases in each category and their percentages. Additionally, it is essential to represent them graphically in a clear way. You can use classic graphs, such as the bar chart or pie chart, but if you want to represent multiple variables simultaneously in a very visual way, some examples are given below:
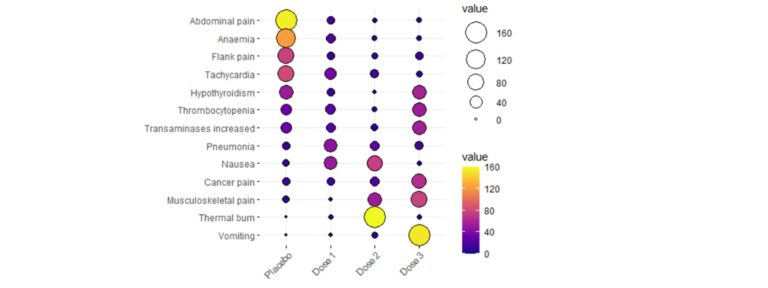
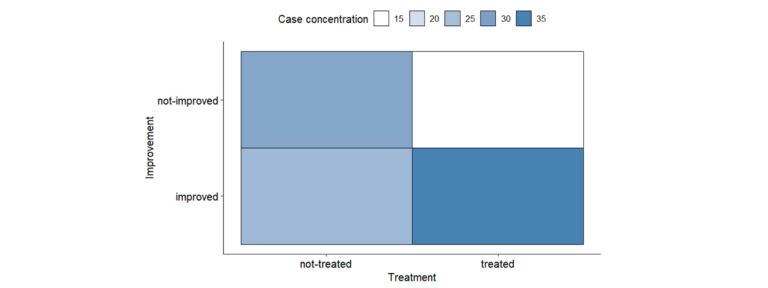
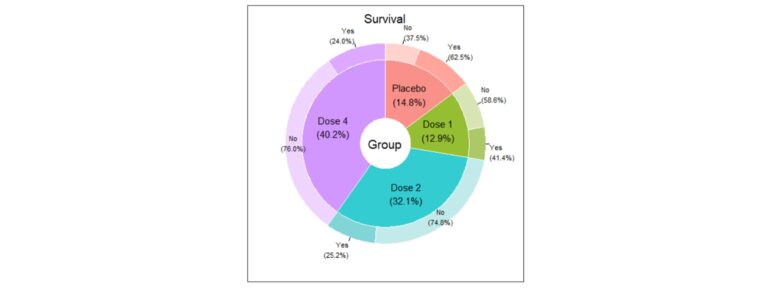
Association between nominal variables – Why can be friends?
The analysis to study the relationship between two nominal variables is often based on the study of the chi-square coefficient. It is one of the best known and widely used analyses in any scientific discipline. This analysis is based on several assumptions, but one of the most important is associated with the expected joint frequencies, according to which no more than 20% of the cells should have an expected frequency of less than 5 cases. When this assumption is not met, the test loses power. When analyzing correlations with this coefficient, a number of nuances must be taken into account:
Since the chi-square coefficient is not bounded (its value ranges from 0 to infinity), it is not possible to study the strength of the correlation, although residual analyses allow us to study the concentration of cases in the cells of the contingency table.
There are other coefficients that make it possible to study the strenght of the association between two nominal variables:
|
Name |
Use |
Range of values |
Interpretation |
Precautions |
|
Phi Coefficient |
2×2 tables |
Between -1 and 1 |
If it approaches -1 the data are grouped in the main diagonal of the contingency table. If it approaches 1, the data are grouped in the secondary diagonal of the contingency table. |
– |
|
Contingency coefficient |
Tables of any size |
Between 0 and 1 |
As it approaches 1, the relationship is more intense |
Its maximum value depends on the size of the table and its maximum can be estimated thanks to the Cmax. To compare tables of different dimensions, the Pawlik’s correction, which ranges from 0 to 1, can be used. |
|
Cramer’s V coefficient |
Tables of any size |
Between 0 and 1 |
As it approaches 1, the relationship is more intense |
– |
|
Tschuprow’s T-coefficient |
Tables of any size |
Between 0 and 1 |
As it approaches 1, the relationship is more intense |
– |
|
Goodman-Kruskal Lambda |
Tables of any size |
Between 0 and 1 |
As it approaches 1, the relationship is more intense |
It requires knowing which is the independent variable and which is the dependent variable. |
|
Yule’s Q coefficient |
2×2 |
Between -1 and 1 |
As it approaches 1, the odds ratio will be greater than 1. As it approaches -1, the odds ratio will be less than 1. |
It requires knowing which is the independent variable and which is the dependent variable. |
|
Uncertainty coefficient (Theil’s U) |
2×2 |
Between 0 and 1 |
Reflects the proportional reduction in error when the values of one variable are used to predict the values of the other variable. |
It requires knowing which is the independent variable and which is the dependent variable. |
If nominal variables change over time… follow them closely!
If you have a nominal variable measured over multiple time periods and you want to study whether there are changes in the distribution of its modalities, there are a series of techniques that allow you to study whether there are significant variations:
|
Name |
Use |
Precautions |
Interpretation |
|
McNemar’s test |
One variable with two modalities (assessment at two different points in time) |
These tests have a series of assumptions that must be monitored in order not to lose statistical power. |
If the test is significant, there will be changes associated with the passage of time in the frequency distribution of the variable being analyzed. |
|
Bowker’s test |
One variable with three or more modalities (assessment at two different points in time) |
||
|
Cochran’s Q test |
One variable with two modalities (assessment at three or more different points in time) |
In case the test is significant, multiple comparisons should be made adjusting the significance level |
A word about odds ratios and the Relative Risk Ratio
In order to understand the concept of odds ratio, it is necessary to understand the following concepts associated with it:
Odds range from 0 to infinity and can be calculated for the occurrence of the event as well as for the non-occurrence of the event. In the example, there would be two odds: the odds of improvement would be 0.60/0.40=1.5 and the odds of no improvement would be 0.40/0.60=0.667. These are interpreted as ratios, i.e., the number of times something can happen over the number of times it cannot happen. In this case, the patient is more likely to improve.
Odds ratios (OR) are the quotient between the two odds and also range from 0 to infinity, but how is an OR interpreted in a basic way?
In the case of the Relative Risk Ratio, it is defined as the quotient of the odds of having the disease or presenting the outcome of interest if the predictive factor –i.e., the risk factor– is present or absent.
To interpret relative risk, let us consider an RR of 2. This result means that the risk in one group is twice as high as in the other group. If it is equal to 1, it is equal for both groups and if it is less than 1, the risk is higher for the other group.
The main difference with the OR is that the Relative Risk Ratio is used primarily in the assessment of prospective studies, while the OR is used primarily in the analysis of retrospective studies.
Can anything else be done with nominal variables?
Of course! The analysis of nominal variables can go beyond studying their descriptive behavior and their bivariate relationship. Some examples of possible analyses are:
Mercedes Ovejero and Jaime Ballesteros
Biostatistics Unit of Sermes CRO

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

These nanotubes, thin structures that connect cells to each other, all...