
En los últimos años, las tecnologías de síntesis del habla han avanzado mucho gracias a las técnicas de aprendizaje profundo. El cambio más importante ha sido la capacidad de entrenar el sistema de síntesis del habla con redes neuronales.
Catotron es el primer sistema de síntesis de voz en catalán basado en redes neuronales. Lo ha desarrollado la cooperativa Col·lectivaT con la participación de miembros del grupo de investigación Natural Language Processing (TALN) del Departamento de Tecnologías de la Información y las Comunicaciones (DTIC) de la UPF y la colaboración de miembros de la UPC.
El objetivo del proyecto ha sido entrenar modelos de sistema del habla en catalán con redes neuronales y publicarlo con licencias de código abierto
Hoy en día, los codificadores de voz se utilizan con los sistemas de síntesis del habla también entrenados con redes neuronales. Desgraciadamente, para entrenar estos sistemas, es imprescindible tener recursos muy importantes como datos o potencia computacional. Es por ello que, salvo los sistemas de habla en inglés, no había ningún modelo publicado con licencias abiertas.
El proyecto "Síntesis del habla contra la brecha digital" fue financiado por el Departamento de Cultura de la Generalitat de Catalunya y gracias a la financiación los investigadores han podido entrenar los modelos de sistema del habla en catalán con redes neuronales y publicarlo con licencias de código abierto.
Un trabajo reciente de Mireia Farrús, hasta agosto 2020 jefe del Laboratorio de Habla Expresiva del TALN, conjuntamente con Baybars Külebi (Col·lectivaT), Alp Öktem, doctor por la UPF (Col·lectivaT), Alex Peiró-Lilja (UPF) y Santiago Pascual (UPC ), ha presentado el sistema a la conferencia internacional Interspeech2020, celebrada de manera virtual del 25 al 29 de octubre desde Shanghai (China).
Las tecnologías de código que han empleado los desarrolladores de Catotron son los repositorios de Tacotron2 y WaveGlow, de la empresa de NVIDIA publicados con licencias abiertas a GitHub. "Uno de los resultados más importantes alcanzados en este proyecto ha sido el código: nuestro fork de Tacotron2, que está modificado para el catalán, imprescindible para utilizar los modelos de catalán", explican los autores del trabajo. "Además, hemos desarrollado un segundo repositorio catotron-cpu, que es ejecutable con los procesadores más comunes, los CPUs. Esta versión de Catotron es una alternativa más ligera y más eficiente que otras ya existentes ", añaden.
Para entrenar los modelos de catalán los investigadores aprovecharon los datos abiertos ya publicadas. Las voces resultantes de la Ona y Pau están entrenadas con los datos de Festcat, un proyecto de la Generalitat, realizado por los investigadores de la UPC.
Además,"Durante nuestras pruebas también hicimos experimentos con el conjunto de datos del ParlamentParla, y produjimos un modelo del habla de Artur Mas, que era la persona con más horas registradas de este conjunto de datos, y aprovechamos esta prueba para hacer una estimación del volumen y de la calidad de datos necesarios para entrenar un modelo ", explican los desarrolladores de Col·lectivaT, líderes del proyecto.
Con las herramientas publicadas en la web de Catotron, es decir el código y los modelos, ya es posible adaptar la voz mediante el aprendizaje por transferencia (transfer learning) a partir de los modelos publicados y grabaciones de un/a locutor/a. "Nuestro ejemplo de catotron-transfer-learning.ipynb explica los pasos necesarios de cómo hacerlo". Está a disposición del público una prueba de síntesis del habla a la que se puede acceder a través de una demo que se encuentra en la web http://catotron.collectivat.cat/, en la que introduciendo un texto escrito, el sistema lo devuelve en forma de texto hablado.
Trabajo de referencia:
Baybars Külebi, Alp Öktem, Alex Peiró-Lilja, Santiago Pascual y Mireia Farrús (2020), "Catotron:A neural text-to-speech System in Catalan", Interspeech2020, 25 al 29 de octubre organizado en Shanghai (China) y llevado a cabo de manera virtual. https://cloud.laklak.eu/s/PTJNAK8ZcX5ZFZX

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
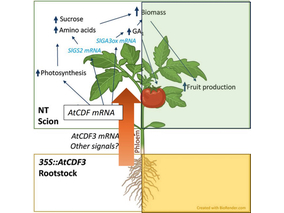
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

New study finds an association between higher temperatures early in li...










