Las redes neuronales surgieron en los años 90 como un algoritmo inspirado en el funcionamiento del cerebro, que tiene como objetivo dotar al ordenador de la capacidad de aprender a partir de ejemplos, emulando, de forma bastante simplista, la manera en la que aprende el ser humano.
Estas redes suponían un gran avance en el plano teórico, pero, lamentablemente, requieren ordenadores de gran potencia y amplias bases de datos, por lo que fueron desechadas a favor de otro tipo de sistemas.
No obstante, desde hace aproximadamente 10 años, las redes neuronales han resurgido con mucha más fuerza, marcando un antes y un después en el campo del aprendizaje automático o machine learning.
Las redes modernas han evolucionado con el tiempo. En la actualidad, cuentan con un gran número de capas y van aprendiendo, de forma sucesiva, niveles de representación de datos cada vez más complejos.
Gracias a estos avances, han mejorado y optimizado su rendimiento en problemas como el reconocimiento de voz, el reconocimiento de imágenes o el reconocimiento de escritura manuscrita, entre otros muchos.
El aprendizaje automático pretende conseguir que sea el propio ordenador quien extraiga, a partir de datos, la información importante; utilizando, para ello, técnicas de reconocimiento de patrones.
Para poder entender mejor las diferencias entre el aprendizaje automático y la programación clásica, pongamos un ejemplo: supongamos que queremos distinguir entre audios con ruido y sin ruido.
En el caso de la programación clásica una persona debe definir qué es el ruido y escribir las instrucciones que el ordenador debe ejecutar para analizar audios y poder clasificarlos correctamente.
En el otro caso, el de la programación mediante aprendizaje automático, un posible método consistiría en mostrar al ordenador, como entrada, 1000 audios ruidosos y 1000 audios limpios, para que, posteriormente y mediante técnicas de aprendizaje, el ordenador fuera extrayendo la información necesaria para discriminar ficheros aún no han sido escuchados.
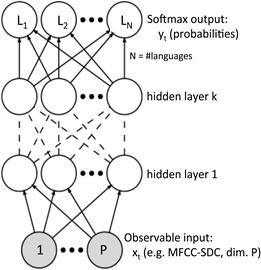
Las redes neuronales constan de varias capas formadas por pequeñas unidades de cómputo que realizan operaciones no lineales.
En la capa inferior se encuentran las entradas a la red, como por ejemplo, nuestro fichero de audio.
Las capas intermedias, denominadas capas ocultas, son las encargadas de realizar los cálculos. Cada unidad recibe como entrada, las salidas de la capa anterior, ponderadas mediante factores multiplicadores llamados pesos, a través de las cuales calcula una salida.
La capa final es la encargada de entregarnos la “solución” al problema que le planteamos a la red.
Los cálculos que realiza cada unidad y los pesos mediante los cuales se ponderan las propagaciones se entrenan de forma automática a partir de ejemplos conocidos; en otras palabras, la red empieza calculando los supuestos resultados de forma aleatoria y, mediante el entrenamiento con muestras conocidas, va ajustando esos pesos para que la salida sea la deseada.
Un grupo de investigadores del “Grupo de Biometría y Reconocimiento de Patrones ATVS” de la Universidad Autónoma de Madrid (UAM - Escuela Politécnica Superior) ha presentado un sistema de reconocimiento de idioma hablado basado en redes neuronales, con resultados muy satisfactorios.
Sólo necesita 3 segundos
El reconocimiento de idioma tiene como objetivo distinguir cuál es el idioma hablado en un segmento de audio.
En un mundo cada vez más globalizado, este tipo de sistemas actúan como una etapa de pre-procesado en sistemas de reconocimiento de voz multilingües (como por ejemplo, “Siri”).
En un artículo publicado recientemente en la revista PLoS ONE, los investigadores han comparado un sistema clásico, cuyo rendimiento está más que demostrado y aceptado en la comunidad, con un sistema basado en redes neuronales.
Para ello, han utilizado audios con una longitud inferior a 3 segundos, que han sido extraídos de una evaluación competitiva organizada por el Instituto de Estándares y Tecnología de Estados Unidos (NIST).
“El sistema ha sido entrenado para distinguir entre 8 idiomas diferentes (inglés, español, dari, francés, pastún, ruso, urdu y chino), utilizando más de 1600 horas de audio en total. Este sistema está basado en un tipo de red neuronal con unidades de memoria (LSTMs, por sus siglas en inglés) que permite extraer información no sólo de la entrada que recibe, sino de una secuencia completa de audio”, explican los investigadores.
Los resultados de este nuevo sistema presentan una mejora relativa de un 26.15% frente al sistema de referencia basado en i-vectors, cuyas distintas variantes han sido el estado del arte durante los últimos años.
El sistema propuesto consigue reconocer correctamente más del 70% de los ficheros, en tan sólo 3 segundos, e incluso más del 50% de los mismos, en menos de 1 segundo.
_____________________
Referencia bibliográfica:
Rubén Zazo, Alicia Lozano, Javier González, Doroteo Torre y Joaquín González: Language Identification in Short Utterances Using Long Short-Term Memory (LSTM) Recurrent Neural Networks. PLoS ONE. DOI: 10.1371/journal.pone.0146917
Imagen: Ejemplo de red neuronal

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
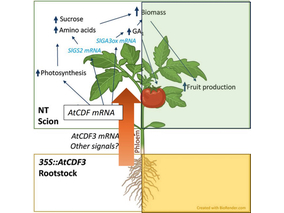
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

Telum Therapeutics, a biotechnology company leveraging proprietary met...