Santiago Marco-Sola, investigador del Departamento de Arquitectura de Computadores y Sistemas Operativos y del Barcelona Supercomputing Center (BSC), y su equipo han desarrollado algoritmos y herramientas computacionales de alto rendimiento que han contribuido a la obtención del primer borrador del pangenoma humano. El estudio, llevado a cabo por un consorcio internacional de investigadores, se ha publicado en la revista Nature.
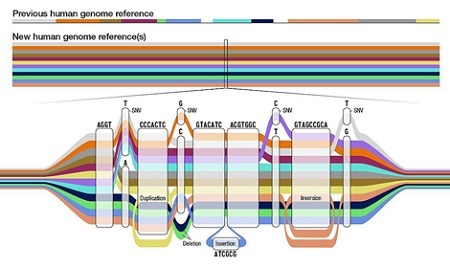
El primer borrador del pangenoma humano, desarrollado por el consorcio Human Pangenome Reference Consortium (HPRC), supera la referencia lineal y basada en pocas personas del primer genoma humano, secuenciado hace dos décadas. Mediante una estructura de grafo, el nuevo pangenoma modela las variaciones genómicas que se dan en diferentes individuos de nuestra especie. En esta primer versión se han reconstruido con alta precisión y fiabilidad los genomas de 47 individuos de varias partes del mundo con ancestros diferentes (africanos, americanos, asiáticos y europeos). El consorcio pretende aumentar esta cifra hasta 350 en los próximos años.
Para entender qué métodos y herramientas eran los más adecuados para la construcción del pangenoma y el análisis posterior, el HPRC ha analizado varios métodos computacionales de alto rendimiento. Uno de los métodos utilizados ha sido el desarrollado por Santiago Marco-Sola y su equipo en la UAB y el BSC: un algoritmo para el alineamiento de secuencias genómicas (WFA, Wavefront Alignment Algorithm), que mejora en eficiencia y escalabilidad a otros métodos.
«La construcción de un pangenoma es compleja y comporta diferentes fases de análisis y procesamiento de datos, dado que requiere procesar enormes volúmenes de datos genómicos. Los métodos y programas para el ensamblado y procesamiento de datos genómicos están compuestos por múltiples fases que requieren usar algoritmos complejos y costosos. Por eso, este proyecto no sería posible sin computadores de altas prestaciones, dado que solo supercomputadores como el Marenostrum4 tienen la capacidad de procesar y almacenar cantidades de datos tan grandes», señala Santiago Marco-Sola.
El estudio del pangenoma publicado añade 119 millones de pares de bases del ADN y 1.115 duplicaciones de genes y aumenta la cantidad de variantes estructurales detectadas en un 104%. Esto permitirá representar decenas de miles de nuevas variantes genómicas en regiones genómicas inaccesibles hasta ahora y acelerar la investigación clínica, al mejorar la comprensión del vínculo entre los genes y los rasgos de las enfermedades.
Imagen: Darryl Leja, National Human Genome Research Institute, NIH
Artículo: Liao, WW., Asri, M., Ebler, J. et al. A draft human pangenome reference. Nature 617, 312–324 (2023). https://doi.org/10.1038/s41586-023-05896-x

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
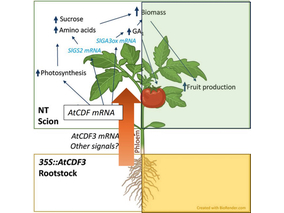
AtCDF3 gene induced greater production of sugars a...
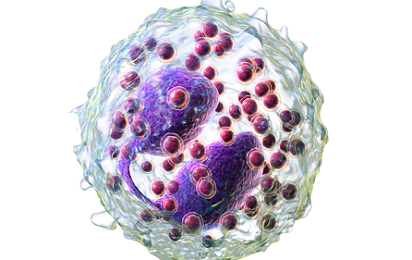
En nuestro post hablamos sobre este interesante tipo de célula del...

Peroxisome proliferator-activated receptors are emerging as a potentia...