There are many genetic causes of cancer: while some mutations are inherited from our parents, others are acquired all throughout our life due to external factors or due to mistakes in copying DNA. Large-scale genome sequencing has revolutionised the identification of cancers driven by the latter group of mutations – somatic mutations – but it has not been as effective in the identification of the inherited genetic variants that predispose to cancer. The main source for identifying these inherited mutations is still family studies.
Researchers have developed a new statistical method to identify cancer predisposition genes from tumour sequencing data. The method allows researchers to find risk variants without a control sample, meaning that they do not need to compare cancer patients to groups of healthy people.
“Our results show that the new cancer predisposition genes may have an important role in many types of cancer. For example, they were associated with 14% of ovarian tumours, 7% of breast tumours and to about 1 in 50 of all cancers. For example, inherited variants in one of the newly-proposed risk genes – NSD1 – may be implicated in at least 3 out of 1,000 cancer patients”, explains Fran Supek, group leader of the Genome Data Science Lab at IRB Barcelona.
The work, which is published in Nature Communications, presents their statistical method ALFRED and identifies 13 candidate cancer predisposition genes, of which 10 are new. “We applied our method to the genome sequences of more than 10,000 cancer patients with 30 different tumour types and identified known and new possible cancer predisposition genes that have the potential to contribute substantially to cancer risk”, says Ben Lehner, principal investigator of the study.
The researchers worked with genome data from several cancer studies from around the world, including The Cancer Genome Atlas (TCGA) project and also from several projects having nothing to do with cancer research.
Reference article:
Solip Park, Fran Supek, and Ben Lehner. ‘Systematic discovery of germline cancer predisposition genes through the identification of somatic second hits’ Nature Communications (2018) 9:2601 | DOI: 10.1038/s41467-018-04900-7
More information: CRG

La mejor actitud que podemos adoptar es la de trat...

The research team observed changes in head circumf...
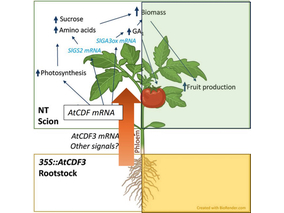
AtCDF3 gene induced greater production of sugars a...
En nuestro post hablamos sobre este interesante tipo de célula del...

Telum Therapeutics, a biotechnology company leveraging proprietary met...